
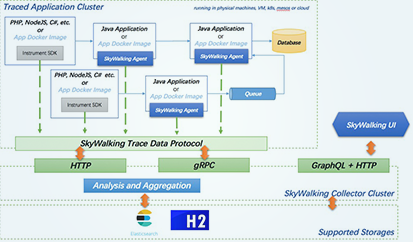
前言碎语
skywalking是个非常不错的apm产品,但是在使用过程中有个非常蛋疼的问题,在基于es的存储情况下,es的数据一有问题,就会导致整个skywalking web ui服务不可用,然后需要agent端一个服务一个服务的停用,然后服务重新部署后好,全部走一遍。这种问题同样也会存在skywalking的版本升级迭代中。而且apm 这种过程数据是允许丢弃的,默认skywalking中关于trace的数据记录只保存了90分钟。故博主准备将skywalking的部署容器化,一键部署升级。下文是整个skywalking 容器化部署的过程。
目标:将skywalking的docker镜像运行在k8s的集群环境中提供服务
docker镜像构建
FROM registry.cn-xx.xx.com/keking/jdk:1.8
ADD apache-skywalking-apm-incubating/ /opt/apache-skywalking-apm-incubating/
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& echo 'Asia/Shanghai' >/etc/timezone \
&& chmod +x /opt/apache-skywalking-apm-incubating/config/setApplicationEnv.sh \
&& chmod +x /opt/apache-skywalking-apm-incubating/webapp/setWebAppEnv.sh \
&& chmod +x /opt/apache-skywalking-apm-incubating/bin/startup.sh \
&& echo "tail -fn 100 /opt/apache-skywalking-apm-incubating/logs/webapp.log" >> /opt/apache-skywalking-apm-incubating/bin/startup.sh
EXPOSE 8080 10800 11800 12800
CMD /opt/apache-skywalking-apm-incubating/config/setApplicationEnv.sh \
&& sh /opt/apache-skywalking-apm-incubating/webapp/setWebAppEnv.sh \
&& /opt/apache-skywalking-apm-incubating/bin/startup.sh
在编写Dockerfile时需要考虑几个问题:skywalking中哪些配置需要动态配置(运行时设置)?怎么保证进程一直运行(skywalking 的startup.sh和tomcat中 的startup.sh类似)?
application.yml
#cluster:
# zookeeper:
# hostPort: localhost:2181
# sessionTimeout: 100000
naming:
jetty:
#OS real network IP(binding required), for agent to find collector cluster
host: 0.0.0.0
port: 10800
contextPath: /
cache:
# guava:
caffeine:
remote:
gRPC:
# OS real network IP(binding required), for collector nodes communicate with each other in cluster. collectorN --(gRPC) --> collectorM
host: #real_host
port: 11800
agent_gRPC:
gRPC:
#os real network ip(binding required), for agent to uplink data(trace/metrics) to collector. agent--(grpc)--> collector
host: #real_host
port: 11800
# Set these two setting to open ssl
#sslCertChainFile: $path
#sslPrivateKeyFile: $path
# Set your own token to active auth
#authentication: xxxxxx
agent_jetty:
jetty:
# OS real network IP(binding required), for agent to uplink data(trace/metrics) to collector through HTTP. agent--(HTTP)--> collector
# SkyWalking native Java/.Net/node.js agents don't use this.
# Open this for other implementor.
host: 0.0.0.0
port: 12800
contextPath: /
analysis_register:
default:
analysis_jvm:
default:
analysis_segment_parser:
default:
bufferFilePath: ../buffer/
bufferOffsetMaxFileSize: 10M
bufferSegmentMaxFileSize: 500M
bufferFileCleanWhenRestart: true
ui:
jetty:
# Stay in `localhost` if UI starts up in default mode.
# Change it to OS real network IP(binding required), if deploy collector in different machine.
host: 0.0.0.0
port: 12800
contextPath: /
storage:
elasticsearch:
clusterName: #elasticsearch_clusterName
clusterTransportSniffer: true
clusterNodes: #elasticsearch_clusterNodes
indexShardsNumber: 2
indexReplicasNumber: 0
highPerformanceMode: true
# Batch process setting, refer to https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/java-docs-bulk-processor.html
bulkActions: 2000 # Execute the bulk every 2000 requests
bulkSize: 20 # flush the bulk every 20mb
flushInterval: 10 # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: 2 # the number of concurrent requests
# Set a timeout on metric data. After the timeout has expired, the metric data will automatically be deleted.
traceDataTTL: 2880 # Unit is minute
minuteMetricDataTTL: 90 # Unit is minute
hourMetricDataTTL: 36 # Unit is hour
dayMetricDataTTL: 45 # Unit is day
monthMetricDataTTL: 18 # Unit is month
#storage:
# h2:
# url: jdbc:h2:~/memorydb
# userName: sa
configuration:
default:
#namespace: xxxxx
# alarm threshold
applicationApdexThreshold: 2000
serviceErrorRateThreshold: 10.00
serviceAverageResponseTimeThreshold: 2000
instanceErrorRateThreshold: 10.00
instanceAverageResponseTimeThreshold: 2000
applicationErrorRateThreshold: 10.00
applicationAverageResponseTimeThreshold: 2000
# thermodynamic
thermodynamicResponseTimeStep: 50
thermodynamicCountOfResponseTimeSteps: 40
# max collection's size of worker cache collection, setting it smaller when collector OutOfMemory crashed.
workerCacheMaxSize: 10000
#receiver_zipkin:
# default:
# host: localhost
# port: 9411
# contextPath: /
webapp.yml
server:
port: 8080
collector:
path: /graphql
ribbon:
ReadTimeout: 10000
listOfServers: #real_host:10800
security:
user:
admin:
password: #skywalking_password
动态配置:密码,grpc等需要绑定主机的ip都需要运行时设置,这里我们在启动skywalking的startup.sh只之前,先执行了两个设置配置的脚本,通过k8s在运行时设置的环境变量来替换需要动态配置的参数
setApplicationEnv.sh
#!/usr/bin/env sh
sed -i "s/#elasticsearch_clusterNodes/${elasticsearch_clusterNodes}/g" /opt/apache-skywalking-apm-incubating/config/application.yml
sed -i "s/#elasticsearch_clusterName/${elasticsearch_clusterName}/g" /opt/apache-skywalking-apm-incubating/config/application.yml
sed -i "s/#real_host/${real_host}/g" /opt/apache-skywalking-apm-incubating/config/application.yml
setWebAppEnv.sh
#!/usr/bin/env sh
sed -i "s/#skywalking_password/${skywalking_password}/g" /opt/apache-skywalking-apm-incubating/webapp/webapp.yml
sed -i "s/#real_host/${real_host}/g" /opt/apache-skywalking-apm-incubating/webapp/webapp.yml
保持进程存在:通过在skywalking 启动脚本startup.sh末尾追加"tail -fn 100 /opt/apache-skywalking-apm-incubating/logs/webapp.log",来让进程保持运行,并不断输出webapp.log的日志
Kubernetes中部署
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: skywalking
namespace: uat
spec:
replicas: 1
selector:
matchLabels:
app: skywalking
template:
metadata:
labels:
app: skywalking
spec:
imagePullSecrets:
- name: registry-pull-secret
nodeSelector:
apm: skywalking
containers:
- name: skywalking
image: registry.cn-xx.xx.com/keking/kk-skywalking:5.2
imagePullPolicy: Always
env:
- name: elasticsearch_clusterName
value: elasticsearch
- name: elasticsearch_clusterNodes
value: 172.16.16.129:31300
- name: skywalking_password
value: xxx
- name: real_host
valueFrom:
fieldRef:
fieldPath: status.podIP
resources:
limits:
cpu: 1000m
memory: 4Gi
requests:
cpu: 700m
memory: 2Gi
---
apiVersion: v1
kind: Service
metadata:
name: skywalking
namespace: uat
labels:
app: skywalking
spec:
selector:
app: skywalking
ports:
- name: web-a
port: 8080
targetPort: 8080
nodePort: 31180
- name: web-b
port: 10800
targetPort: 10800
nodePort: 31181
- name: web-c
port: 11800
targetPort: 11800
nodePort: 31182
- name: web-d
port: 12800
targetPort: 12800
nodePort: 31183
type: NodePort
Kubernetes部署脚本中唯一需要注意的就是env中关于pod ip的获取,skywalking中有几个ip必须绑定容器的真实ip,这个地方可以通过环境变量设置到容器里面去
文末结语
整个skywalking容器化部署从测试到可用大概耗时1天,其中花了个多小时整了下谭兄的skywalking-docker镜像(https://hub.docker.com/r/wutang/skywalking-docker/),发现有个脚本有权限问题(谭兄反馈已解决,还没来的及测试),以及有几个地方自己不是很好控制,便build了自己的docker镜像,其中最大的问题还是解决集群中网络通讯的问题,一开始我把skywalking中的服务ip都设置为0.0.0.0,然后通过集群的nodePort映射出来,这个时候的agent通过集群ip+31181是可以访问到naming服务的,然后通过naming服务获取到的collector gRPC服务缺变成了0.0.0.0:11800, 这个地址agent肯定访问不到collector的,后面通过绑定pod ip的方式解决了这个问题。
