
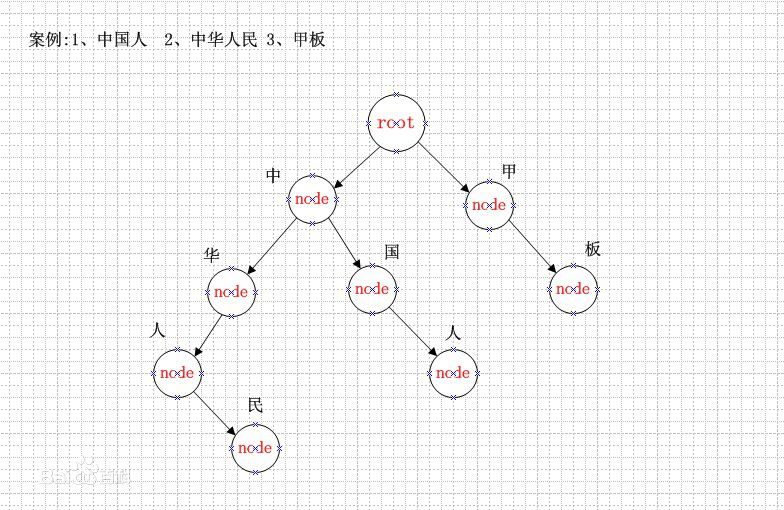
前言
对于中文分词这个字眼,百科是这么描述的:
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
简单的说,就是把一个句子拆分成多个词,有废话的赶脚,呵呵
之前几篇博文,笔者都是用的Lucene里的StandardAnalyzer来做的分词处理,虽然在后面的Lucene版本中,
准备工作
这里先把这两个分词器加入到我们的项目中来
IKAnalyzer:IKAnalyzer是一个国人开发的开源的分词工具,下载地址:https://code.google.com/archive/p/ik-analyzer/downloads?page=1,GItHub地址:https://github.com/wks/ik-analyzer。推荐到GitHub上下载源码然后自己打包,项目是maven构建的,打成jar,然后在我们的项目中引用。
ps:打包项目的时候记得去掉test
paoding:paoding也是一个开源的i项目,下载地址:https://code.google.com/archive/p/paoding/downloads,下载下来是一个压缩文件,里面有源码也有打包好可以直接用的jar
ps:下载paoding的时候请自行翻墙吧,这里推荐一个翻墙神器Lantern
进入正文
笔者在测试过程中并不是一番风顺啊,好多坑,下面我们来看看这些坑
IKAnlyzer的问题:
1.最新的项目也是基于Lucene3.0.3版本的,而笔者一直都是使用的最新的Lucene5.5,所以一测试就报了如下的错误
Exception in thread "main" java.lang.VerifyError: class org.wltea.analyzer.lucene.IKAnalyzer overrides final method tokenStream.(Ljava/lang/String;Ljava/io/Reader;)Lorg/apache/lucene/analysis/TokenStream;
解决:笔者有试着将IKAnlyzer项目的Lucene版本换成5.5的重新打包,然后发现行不通,改动的地方太多了,虽然IKAnlyzer项目不大,文件不多。笔者还没达到重写IKAnlyzer项目的能力,有时间可以研究研究源码,最后只有降级自己的Lucene版本了,幸好有maven,降级只要改下pom.xml就行了
paoding的问题
1.项目首先会依赖apache的commons-logging,笔者测试1.1版本通过。
2.然后就是下面的这个了 问题了,其实这个问题paoding自己的使用文档中类似的说明,(Paoding中文分词参考手册.htm)这个文档包含在了下载的压缩包中了
net.paoding.analysis.exception.PaodingAnalysisException: please set a system env PAODING_DIC_HOME or Config paoding.dic.home in paoding-dic-home.properties point to the dictionaries!
解决:就是指定paoding的一个字典文件目录,这个文件在下载下来的压缩包中的dic中,
三种解决方案:
(1).你可以解压缩jar,然后把paoding-dic-home.properties文件中的paoding.dic.home指定你的doc目录,重新压缩,把后缀换成jar就行了。
(2).就是参照官方的说明,把doc目录添加到环境变量中
(3).把doc放在项目目录下
3.paoding还有个问题就是Lucene3.0.3都不兼容了,笔者只好又把Lucene版本降到2.2.0来测试了
越过那些沟沟坎坎终于要见真功夫了,不多说,直接上代码,上图
package com.kl.Lucene;
import net.paoding.analysis.analyzer.PaodingAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Token;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.TermAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.StringReader;
/**
* @author kl by 2016/3/14
* @boke www.kailing.pub
*/
public class AnalyzerTest {
//测试数据
public static String testData="中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一" +
"一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。";
/**
* 得到IKAnalyzer分词器
* @return
*/
public static Analyzer getIKAnalyzer(){
return new IKAnalyzer();
}
/**
* 得到Paoding分词器
* @return
*/
public static Analyzer getPaoding(){
return new PaodingAnalyzer();
}
/**
* 测试IKAnalyzer
* @throws Exception
*/
@Test
public void TestIKAnalyzer()throws Exception{
Analyzer analyzer =getIKAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("", new StringReader(testData));
tokenStream.addAttribute(TermAttribute.class);
System.out.println("分词数据:"+testData);
System.out.println("=====IKAnalyzer的分词结果====");
while (tokenStream.incrementToken()) {
TermAttribute termAttribute = tokenStream.getAttribute(TermAttribute.class);
System.out.println(new String(termAttribute.term()));
termAttribute.termLength();
}
}
/**
* 测试Paoding
* @throws Exception
*/
@Test
public void TestPaoding()throws Exception{
Analyzer analyzer =getPaoding();
TokenStream ts = analyzer.tokenStream("", new StringReader(testData));
System.out.println("分词数据:"+testData);
System.out.println("=====Paoding的分词结果====");
Token t;
// while ((t = ts.next()) != null) {
// System.out.println(t.termText());
// }
}
}
测试数据:中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
测试结果如下:


从结果上看,IKAnalyzer和paoding的分词相差无几,IKAnlyzer比paoding的分词粒度更细,这个可以查看他们的分词字典文件去分析
后记:除了上面介绍的两种分词,常用的还有中日韩二元分词器CJKAnalyzer,以及lucene基于中科院分词实现的SmartChineseAnalyzer,其中cjk在lucene-common的jar包里了,SmartChineseAnalyzer需要另外引入jar,如下pom依赖
<!--公共的分词器,包含大多数的语言分词-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.5.0</version>
</dependency>
<!--基于中科院的中文分词-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>5.5.0</version>
</dependency>
